스프링 배치 대용량데이터 처리 성능 개선기 [1편]
요구사항
혜택 고객 선정 모델을 통해 혜택 대상 고객들을 선정하고, 해당 고객들에게 쿠폰을 발급해주는 시스템을 구축해야 했다. 여기서 나는 일배치를 통해 집계된 대상 고객들에게 쿠폰을 발급하는 시스템을 설계하고 개발하기로 했다. 그런데 문제는 일별로 발급대상 데이터의 건수가 수십-수백만까지 예상되며 이를 3시간 내에 처리해야한다는 것이었다.
알던 이전에 구축해놓은 스프링 배치 서버가 있어 이를 활용해보기로 했고 전반적인 시스템 구조부터 그려봤다.
Overall System Architecture

스프링 배치 관리/모니터링 도구로는 젠킨스를 활용하고 있다. 배치가 실행되면
- 대상고객이 집계되어있는 DB에서 타겟을 가져와서
- 쿠폰발급 서버에 1건 단위로 발급을 요청한다
- 발급 결과(쿠폰번호)를 받으면
- 데이터 집계 DB에 쿠폰발급상태(완료/실패)를 update해주고
- 발급된 데이터를 Application 조회용 DB에 insert 한다
여기까지 처리하면 배치가 완료 되는 것이다. 이제 전체 Job을 적절한 Step 단위로 나누면 됐는데, 다음과 같이 DB를 기준으로 나누었다.
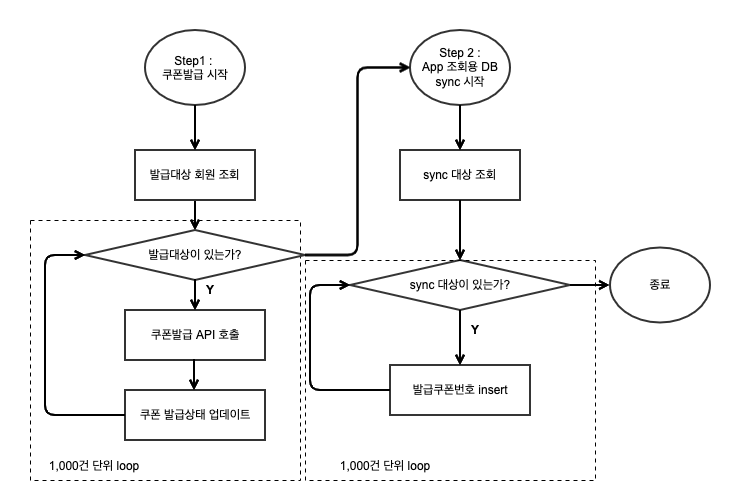
Step을 두개로 나눔으로써 각 Step이 실패했을때 전체 Job을 재실행할 필요 없이 해당 Step만 독립적으로 재실행 가능한 구조를 만들었다. 예를들면 쿠폰발급이 완료된 이후, 조회용 DB 동기화 Step에서 실패를 할 경우에는 처음부터 쿠폰을 발급할 필요없이 동기화 Step만 재실행하면 되는 것이다.
성능 개선 1 : 쿠폰발급 API 병렬 호출
쿠폰발급 서버는 단건 호출만을 지원하며, 응답속도는 평시 30-40ms 수준이다. 건별로 동기호출시 단순 계산을 해봐도 초당 30건 내외밖에 처리를 하지 못한다. 최대 100만건의 데이터를 처리해야한다고 봤을때 이 수준의 성능으로는 쿠폰발급 요청 및 처리에만 10시간 이상이 소요될 것이다.
따라서 병럴 처리가 이루어져야 되는데 찾아보니 Spring batch에서 공식적으로 지원하는 Scaling 방법은 여러가지가 있었다.
- Multi Threaded Step
- AcyncItemProcessor/AcyncItemWriter
- Remote Chuncking
- Partitioning
Remote Chunking은 또 다른 인프라(큐, 배치서버) 구축을 필요로 하며, Partitioning이나 Multi Threaded Step은 작업 전체를 병렬 처리한다. 반면 AcyncItemProcessor/AcyncItemWriter는 ItemProcesso만 병렬 처리하여 부분적으로 Scaling이 가능한 구조이다. 쿠폰발급 Step의 SD를 보자.
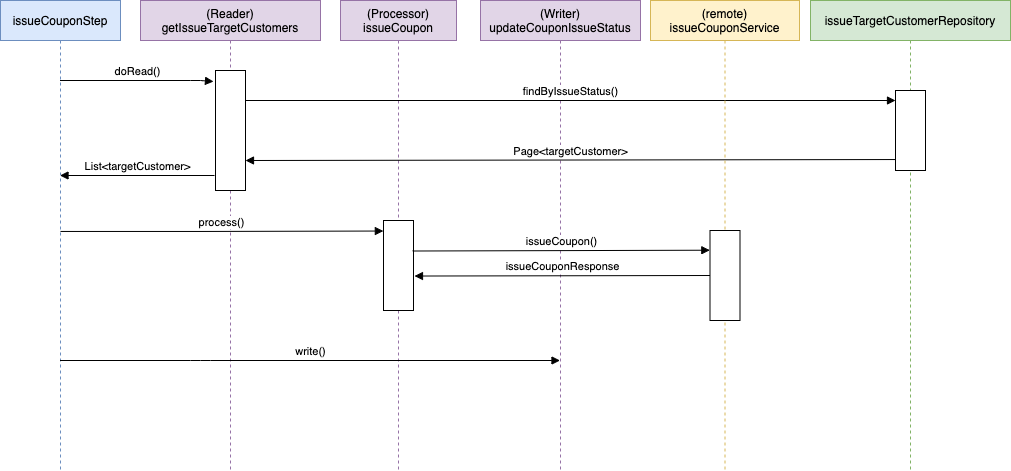
Item Processor에서 쿠폰발급 API를 호출하는 것 외에 병목 지점은 없다. 따라서 부분적으로 병렬 실행이 가능한 AcyncItemProcessor/AcyncItemWriter를 활용해보기로 했다. 적용은 다음 코드만 추가해주는 것으로 돼서 어렵지 않았다.
@Bean
public TaskExecutor asyncTaskExecutor() {
ThreadPoolTaskExecutor executor = new ThreadPoolTaskExecutor();
executor.setCorePoolSize(MAX_POOL_SIZE-5);
executor.setMaxPoolSize(MAX_POOL_SIZE);
executor.setThreadNamePrefix("multi-thread-");
executor.setQueueCapacity(MAX_QUEUE_SIZE);
executor.initialize();
return executor;
}
@Bean
public ItemProcessor<TargetCustomer>, Future<TargetCustomer>> asyncItemProcessor(){
AsyncItemProcessor<TargetCustomer, TargetCustomer> asyncItemProcessor = new AsyncItemProcessor<>();
asyncItemProcessor.setDelegate(issueCoupon());
asyncItemProcessor.setTaskExecutor(asyncTaskExecutor());
return asyncItemProcessor;
}
@Bean
public ItemWriter<Future<TargetCustomer>> asyncItemWriter(){
AsyncItemWriter<TargetCustomer> asyncItemWriter = new AsyncItemWriter<>();
asyncItemWriter.setDelegate(updateIssueCouponStatus());
return asyncItemWriter;
}
asyncItemProcessor를 정의해주면 dispatcher로 작동하여 원래 선언했던 processor를 multi thread로 호출해준다. asyncItemProcessor와 asyncItemWriter는 for-join 방식으로 작동하여 모든 쓰레드의 processor 실행이 끝나면 모아서 한꺼번에 writer에 전달해준다. 결과적으로는 ItemProcessor에 해당하는 코드만 병렬 실행되는 것이다.
이럴게 thread수를 적절히 세팅하여 테스트를 했다. thread수를 5로 세팅하는 경우를 가정했을때, 100만건 발급에 10시간 이상 소요되는 쿠폰발급이 2시간 내외로 줄어들 것으로 기대되었다. 실제 스테이지 환경에서 테스트를 진행해보았고 아래와 같이 prosessor가 다중스레드로 실행되는 것을 확인할 수 있었다. 주의할 것은 TaskExecutor 정의시 SimpleAsyncTaskExecutor를 사용해선 안된다. SimpleAsyncTaskExecutor는 스레드를 계속해서 만들어내는 방식이기 때문에 운영 환경에서 심각한 장애를 유발할 수 있다.

이렇게 쿠폰발급 API 호출은 비동기 처리하여 성능을 개선할 수 있었다. 그런데, 뜻밖에도 쿠폰발급상태를 update하고 발급 완료 데이터를 App 조회용 DB에 insert하는 쿼리의 수행시간이 비정상적으로 길어 이 또한 원인을 찾아봐야만 했다.
참고