레거시 코드 개선기(feat. 스프링 부트, JPA)
레거시를 버려야 할 때
오랜 시간 문제없이 돌아가는 레거시 코드는 낡았지만 돈을 벌어다 주는 고마운 존재다. 물론 낡을대로 낡은 레거시 코드는 볼때마다 갈아엎고 싶은 생각이 가득하지만, 잘 돌아가는 코드를 뒤엎기에는 개발자는 할 일이 너무 많다.
하지만 계속 운영되기만 하면 될게 아니라 요구 사항이 계속 추가되거나 수정되어야 하는 경우가 바로 분명한 동기가 생기는 시점이다. 깔끔하고 확장 및 수정이 쉬운, 세련된 코드로 탈바꿈 할 때가 온 것이다.
문제점 파악
개선 대상 서비스는 '오늘의 팁'이라는 판매자용 서비스다. 판매자들이 백오피스에 접속했을때 지난주 유입 고객들이 얼마나 되며, 이번주의 인기 카테고리는 무엇인지 등 판매 활동 개선에 필요한 팁들을 제공한다. 문제는 아직 새로운 팁 종류를 추가하거나, 로직 수정이 필요한 요구 사항들이 꾸준히 들어오고 있음에도 수정 작업이 엄두가 안날 정도로 낡은 레거시라는 것이다.
그렇다면 무엇을 어떻게 개선하면 될까?
1. Monolithic 구조

몇 년전부터 회사에서도 MSA 전환을 시작하여 우선순위별로 꾸준히 서비스를 분리해내고 있지만 아직도 많은 레거시 코드가 존재한다. 오늘의 팁 또한 미처 떼어나지 못한 서비스인 것이다. 많은 서비스/도메인이 하나의 프로젝트에 엉켜있다보니 소스가 방대하여 빌드가 오래걸린다. 당연히 배포도 느리니 긴급한 이슈에 빠르게 대응하기도 어렵다. 또한, 다른 개발자가 반영한 소스에 문제가 발생해도 내 반영분까지 같이 롤백되는 경우도 있다.
또한, 하나의 데이터베이스에 모든 쿼리 부하가 집중되는 구조 역시 바람직하지 못하다.
2. 무거운 쿼리
레거시 코드의 문제점 중 하나는 너무도 무거운 DB 쿼리에 의존하고 있었다는 것이다. 불필요한 필드를 Select하며, 데이터의 Parsing이나 Null 처리까지 모두 쿼리에서 이루어지고 있었다. 심지어 비즈니스 로직이 쿼리로 구현되어 있기도 했다.
SELECT NVL(PRODUCT_NM) AS PRD_NM,
TO_CHAR(SYSDATE-7, 'YYYY-MM-DD') || '~' || TO_CHAR(SYSDATE-1, 'YYYY-MM-DD') AS SELL_DATE,
CASE WHEN
.
.
.
FROM ( SELECT *
FROM PRODUCT_DETAIL,
WHERE REGIST_DATE BETWEEN SYSDATE-30 AND SYSDATE-1
PRICE > 1000 ) A,
PRODUCT_SELL_STATISTIC B,
.
.
.
이렇게 복잡도가 지나치게 높은 쿼리는 읽기 어려우며 테스트도 어렵기 때문에 수정이 어렵다. 결과적으로 유지보수성이 떨어지게 된다. 몇백라인의 쿼리를 수정할 엄두가 나겠는가?
3. Trasaction Script
그러면 자바 소스는 비교적 단조로워 진다. 비즈니스 로직과 데이터 파싱을 다 쿼리에서 처리하므로 자바 소스는 여러 쿼리를 순차적으로 읽어들이는 트랜잭션 스크립트에 불과하다. 복잡하고 긴 조건에 따라 쿼리를 수행하는 코드가 수백라인에 걸쳐 반복될 뿐이다. 마찬가지로 읽기 힘들며, 단위 테스트 또한 어려워진다.
객체지향 언어를 사용하는 것은 중복/반복을 최소화하고 확장 가능하도록 소스를 구조화하는데 의의가 있다고 생각한다. 수백라인짜리 트랜잭션 스크립트를 짤 것이라면 자바를 쓸 필요도 없다.
4. 읽기 어려운 코드
예컨대 getInformation() 이라는 메서드를 본다면 메서드명만으로 얻을 수 있는 정보가 거의 없다. 무슨 정보를 읽는 다는 것인가? 불행히도 이렇게 식별성이 떨어지는 코드가 곳곳에 산재해 있었다. 변수명, 메서드명만 잘 지어줘도 코드 가독성이 몰라보게 개선된다. 로버트 마틴은 클린코드가 소설처럼 읽기 쉬운 코드라고 했다.
개선
1. MSA 전환

우선 '오늘의 팁' 코드를 레거시 프로젝트에서 적절한 MSA 도메인 API로 이관하였다. 각 API 서버가 독립적으로 빌드/배포되기 때문에 배포가 하루종일 걸릴 일도 없어졌다. 그러면서 MAINDB에 있던 테이블들은 개별 서비스 DB로 이관하였다. 레거시에서는 필요한 모든 데이터를 얻기 위해 직접 쿼리를 했지만 MSA 구조에서는 API 호출을 통해 데이터를 호출한다. 도메인 데이터에 대한 정합성도 개별 API에서 책임진다.
또한 MAINDB는 방대한 데이터들이 있기 때문에 사고/장애에 대한 리스크도 커 엄격한 접근 통제 절차를 두고 관리하고 있다. 하지만 개별 서비스 DB는 각팀에 어느 정도 자율성이 보장되어 이전보다 자유롭게 DB 접근이 가능해졌다.
짧게 이야기하고 넘어가지만 그렇다고 MSA가 능사라는 것은 물론 아니다. 우선 각 도메인 서버에 API 호출을 하여 데이터를 조합하는 것이 성능적으로 손해를 볼 여지도 있고, 트랜잭션 관리 이슈 또한 MSA 구조의 문제점이다. 물론 그럼에도 불구하고 위에서 언급한 이점들이 크다고 생각하여 MSA 이관을 한 것이다.
2. JPA 전환
크고 무거운 네이티브 쿼리부터 손을 쓰기로 하였다. 우선 모든 쿼리문과 사용 테이블을 추출했고, 각 쿼리에서 필요한 데이터가 무엇인지 파악해 문서화하였다. 그리고 이를 바탕으로 쿼리를 간소화하기 시작했다.
먼저 비즈니스 로직과 데이터 파싱을 위한 구문을 걷어내기 시작했다. 이러한 로직은 자바 코드로 위임하여도 전혀 문제가 없다. 상품, 회원 데이터 등은 각 도메인 API 호출을 통해 얻어낼 수 있으므로 상당수 join문도 걷어낼 수 있었다. 쿼리를 간소화하니 JPA 전환이 가능해졌고, 네이티브 쿼리를 Spring Data JPA로 대체해나갔다.
public interface ProductSellStatistic extens JpaRepository<ProductSellStatistic, Integer> {
Optional<ProductSellStatistic> findByMemberNoAndProductNo(int memberNo, int productNo);
List<ProductSellStatistics> findAllByMemberNo(int memberNo);
}
물론 Spring Data JPA만로는 해결이 안되는 경우도 있다. 특히 성능적인 이슈가 우려될 때인데, 그런 경우 QueryDSL로 해결이 가능했다. QueryDSL로 어느정도 복잡도 있는 쿼리를 구현해낼 수 있고 Native hint도 적용 가능하다. 그럼에도 불구하고 네이티브 쿼리를 써야만 하는 상황이 있을 수는 있겠지만 매우 드문 경우라는 생각이 든다. 수백라인의 복잡한 쿼리도 결국 자바 코드로 위임 가능한 구문들을 걷어내고 나면 JPA로 전환이 가능할만큼 간소화되었다.
3. 코드 구조화
코드 구조화를 통해 중복/반복을 최소화하고 싶었다. 일단 눈에 들어오는 것은 수백라인에 걸쳐 조건문을 돌며 판매자에게 노출시켜줄 적절한 '오늘의 팁'을 선정하는 로직이었다. 대강 수도코드로 구현해보자면
노출 대상 립 리스트 선언
if(신규 판매자라면){
첫 판매를 위한 팁 추가
}
if(지난 주 상품 만족도 점수가 낮아졌다면){
if(가격 점수가 낮아졌다면){
적절한 가격 설정에 관한 팁 추가
} else if(배송 점수가 낮아졌다면){
적절한 배송 소요 기간에 관한 팁 추가
}
}
if(광고 서비스를 이용중인 판매자라면){
if(지난 주 광고 실적이 있으면){
광고 실적에 관한 팁 추가
}
}
.
.
.
위와 같은 로직이 수백 라인에 걸쳐 단일 메서드에서 처리되고 있었다. 그런데 바깥쪽 if문끼리는 서로 연관성이 없고, 로직의 패턴도 일관되어서 추상화가 가능해보였다.
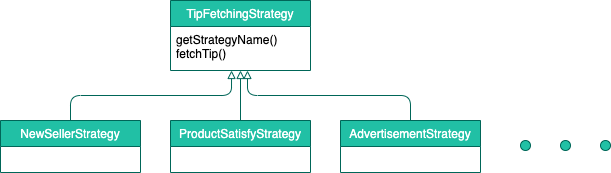
단일 메서드에 길게 늘어져있던 분기문이 깔끔하게 구조화 되었고, 각 객체별로 단위 테스트도 작성할 수 있게 되었다. 새로운 팁이 추가하거나 제거하는 요건이 발생해도 새로운 Strategy 객체를 추가하거나 제거하면 된다.
또한, 새로운 Strategy가 추가되거나 제거되더라도 이를 사용하는 상위 클래스는 변경이 필요 없도록(의존 관계가 없도록) StrategyManager를 추가하였다.
@RequiredArgsConstructor
@Component
public class TipFetchingStrategyManager {
private final ListableBeanFactory beanFactory;
private Map<String, TipFetchingStrategy> strategyMap;
@PostConstruct
public void createStrategyMap() {
strategyMap = new HashMap<>();
strategyMap = beanFactory.getBeansOfType(TipFetchingStrategy.class)
.values()
.stream()
.collect(Collectors.toMap(TipFetchingStrategy::getStrategyName, strategy -> strategy));
}
public Map<String, SalesTipFetchStrategy> getStrategyMap() {
return strategyMap;
}
}
나머지 코드도 중복/반복 되는 지점을 찾아서 구조화하는 작업을 통해 단위 테스트가 가능하며, 수정/확장이 용이한 코드로 개선해나갔다.
기타 개선 포인트
1. 캐시
무거운 쿼리를 간소화시키긴 했지만 앞서 언급한것처럼 성능적으로는 손해를 볼 여지가 있다. 이에 대한 보상 차원으로 DB 접근 자체를 최소화하여 응답 시간을 줄여보기로 했다. 각 WAS 인스턴스의 local memory를 1차 캐시, Redis를 2차 캐시로 하는 multi level 캐시를 적용하였다.
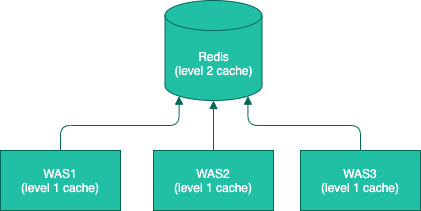
차례대로 Local memory를 먼저 찾고, miss가 나면 저장 후 Redis를 보게 된다. Redis에서 캐시 데이터가 있으면 이를 내려주고 없으면 저장한다. 이런 구조로 miss를 최소화하며 성능적으로도 이득을 볼 수 있었다.
2. Enum
public enum TipCode implements EnumModel {
NEW_SELLER("01")
PRODUCT_SATISFIED("02")
ADVERTISEMENT("03")
.
.
.
레거시에서는 의미를 알기 어려운 여러 상수들이 코드에 산재해 있었다. 이런 상수들이 더 이상 코드 여기저기에 돌아다니지 않도록 Enum으로 만들어 관리했다. 이것만으로도 일단 코드의 가독성이 좋아지며, value 순회 등 enum 클래스가 제공하는 여러 편의 기능도 사용 가능하다.
3. Null 처리
레거시 코드에서는 주로 쿼리 레벨에서 Null 처리(NVL 구문 등)를 하고 있었다. 이를 자바 로직으로 넘기면서 Optional을 적극 활용했다. 아래와 같이 Entity를 읽어들일때부터 Optional로 리턴하게 했다.
public interface ProductSellStatistic extens JpaRepository<ProductSellStatistic, Integer> {
Optional<ProductSellStatistic> findByMemberNoAndProductNo(int memberNo, int productNo);
List<ProductSellStatistics> findAllByMemberNo(int memberNo);
}
일단 Optional을 리턴하면 상위 레이어에서 다시 Optional을 리턴하거나 orElse(), orElseThrow() 등으로 Null 처리를 해야하므로(물론 '명시적'으로 무시할 수는 있다) 보다 Null Safe한 코드를 만드는데 도움이 된다.
배포를 앞두고
문서화
어떤 부분을 어떻게 개선했는지 비기술적인 용어로 설명하는 문서를 작성했다. 그냥 레거시 개선했다고 하면 기획에서 듣기에는 너무도 추상적일 것이다. 서비스를 이렇게 개선했기 때문에 앞으로 얻을 수 있는 효과는 어떤 것들이 있는지를 적었다.
또한 실제 서비스 상황과는 align이 안되는 '낡은 코드'들을 개발 레벨에서 현행화한 내용도 정리했다. 이 중 기획에서 판단이 필요한 내용들은 따로 표시해서 공유했다.
테스트
단위 테스트를 꼼꼼히 했지만 여전히 통합 테스트는 필요하다. 요청/응답 인터페이스는 동일한 구조이기 때문에 as is와 to be API를 동일한 파라미터로 호출해보는 테스트를 여러가지 시나리오로 반복하였다. 또한, 성능적인 이슈가 없는지를 확인하기 위해 jMeter로 반복 호출을 시도해보았다.
그럼에도 불구하고 첫 배포에서 Null Point Exception이 발생하여 한 차례 롤백을 해야했다. 특정 조건에서 발생하고 있었는데, 단위 테스트를 조금 더 밀도있게 했더라면 잡을 수 있었을 것 같았기 때문에 아쉬웠다. 다행히 발생 빈도가 높지는 않았고 큰 이슈도 아니었어서 빠르게 수정 후 재배포를 했다.
리펙토링은 계속된다
첫 술에 배부를 수는 없다. 중요도가 떨어지거나 복잡성이 상대적으로 높지 않은 코드들은 레거시를 그대로 가져가기도 했다. 당장의 우선순위가 높지 않지만 앞으로 리펙토링이 필요하거나 개선 여지가 있어보이는 코드들에는 TODO로 마킹을 해두었다. 리펙토링은 계속된다.