JPA를 처음 접했던 몇 년전에는 ORM이라는 개념 자체가 낯설었다. 엔티티 정의후 연관 관계만 잘 매핑하면 소스에 직접 쿼리를 쓸 일이 현저히 줄어들어 그것만으로도 훌륭하다고 생각했는데, 알고보니 주인공은 영속성 컨텍스트였다. 그만큼 영속성 컨텍스트는 JPA를 사용한다고 하면 반드시 알아야하기 때문에 핵심 개념을 중심으로 정리해보았다.
Entity Manager
엔티티는 말그대로 엔티티의 CRUD에 관여하며 엔티티와 관련된 모든 일을 처리한다. 자바 ORM 표준 JPA 프로그래밍이라는 책에서 김영한님은 엔티티 매니저를 가상의 데이터베이스로 생각하자고 하셨다. 실제 DB에 쿼리가 날아가기 전에, 엔티티와 관련된 모든 생성, 조회, 수정, 제거 작업은 엔티티 매니저를 거치게 된다. 스프링에 익숙하신 분이라면 Bean을 관리하는 스프링 컨테이너 역할정도로 생각해도 무방할 것 같다.
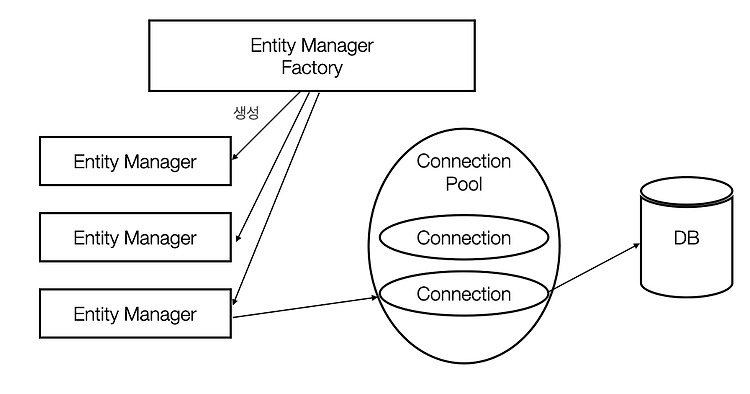
이 엔티티 매니저는 Entity Manager Factory를 통해 생성되게 된다. 여기서 단일 애플리케이션에 엔티티 매니저 팩토리는 하나 있어야 하지만, 엔티티 매니저는 스레드간 공유가 불가능하므로 여러개가 존재할 수 있다.
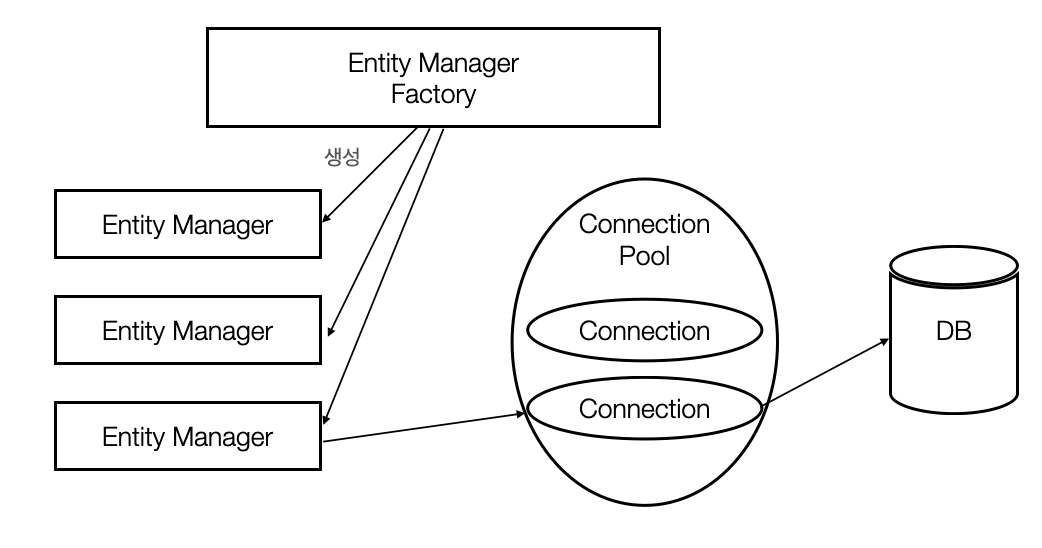
위 그림을 보면 엔티티 매니저가 가상 데이터베이스라는 개념이 이해가 된다. 엔티티 매니저는 엔티티에 변경이 일어났을 때, 해당 내용을 일단 담아둔다. 그리고 필요한 시점(Commit)에 커넥션을 맺어 DB에 담아둔 내용을 모두 반영한다.
영속성 컨텍스트(Persistant Context)
영속성 컨텍스트란 엔티티 매니저가 앤티티를 관리하는 환경, 즉 컨테이너 개념이다. 엔티티를 조회하거나 저장하게 되면 엔티티 매니저는 이 영속성 컨텍스트에 엔티티를 담아두고 관리하게 된다. 위에서 얘기했지만 JPA에서는 저장 요청이 발생한다고 해서 즉각적으로 DB에 반영되는 것이 아니다. 일단 이 영속성 컨텍스트에 보관을 하고 있다가 commit을 하면(내부적으로는 flush()가 호출되면) 영속성 컨텍스트에 담긴 내용을 DB에 반영한다.
1차 캐시(Level 1 Cache)

엔티티 매니저는 엔티티를 일단 담아둔다고 했는데, 영속성 컨텍스트 내 1차 캐시라는 공간에 엔티티를 보관한다. 예시로 실제 조회가 일어날 때의 동작을 보자.
- "order2"라는 id로 엔티티를 조회한다.
- 엔티티 매니저가 영속성 컨텍스트 내의 1차 캐시를 먼저 살펴본다. 1차 캐시에 "order2"라는 id를 가진 엔티티가 존재한다면 바로 해당 엔티티를 반환한다.
- 만약 1차 캐시에 엔티티가 없다면 DB에서 데이터를 읽어온다. 그리고 해당 데이터로 엔티티를 생성하여 1차 캐시에 보관한 뒤 엔티티를 반환한다.
이렇게 1차 캐시에 엔티티를 저장하게 되면 우선 같은 엔티티를 다시 조회하게 될때 DB를 거치치 않으므로 성능상 이점도 있지만 그보다 수정 요청을 할때 진가를 발휘한다.
변경 감지(Dirty Checking)
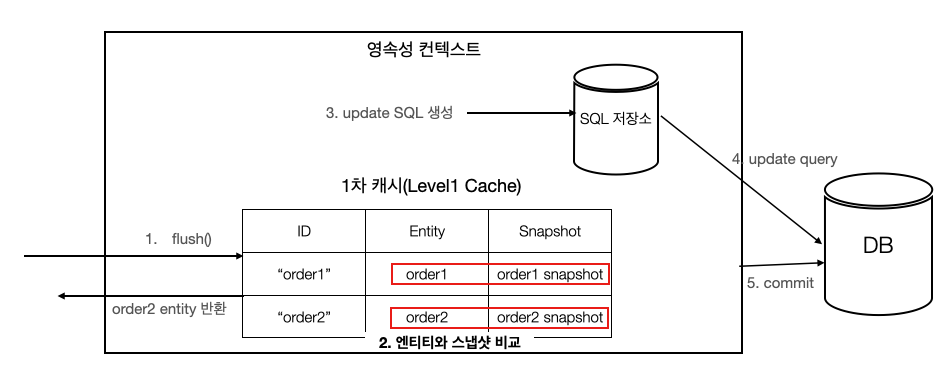
order1과 order2 entity의 내용을 변경하였다. 이 변경 사항을 DB에 업데이트하기 위해 개발자가 임의적으로 업데이트 동작을 유발할 필요가 없다. 엔티티 매니저가 알아서 엔티티의 변경 사항을 감지하여 DB에 업데이트 쿼리를 요청하기 때문이다. 이를 변경감지라고 하는데, 다음과 같은 방식으로 동작한다.
- order1과 order2 엔티티의 내용이 변경된다.
- 트랜잭션을 커밋한다. (내부적으로 flush() 메서드 자동 호출)
- 엔티티 매니저가 1차 캐시의 엔티티들과 스냅샷을 비교하여 변경이 일어난 엔티티를 찾는다.
- 변경이 일어난 엔티티에 대해 update SQL을 작성하여 SQL 저장소에 저장한다.
- SQL 저장소에서 업데이트 쿼리를 DB에 보낸다.
- 데이터베이스 트랜잭션을 커밋한다.
이렇듯, 엔티티 매니저가 알아서 엔티티의 변경 내역을 감지해서 DB에 수정 쿼리를 보낸다. 코드로 구현해보면 아래와 같다.
@Transactional
public void updateOrder(Long orderId, String name, OrderStatus orderStatus, Member orderMember){
Order order = orderRepository.findOne(orderId);
order.setStatus(orderStatus);
order.setMember(orderMember);
}
코드에서 주의할 점은 수정할 order 엔티티를 엔티티 컨텍스트에서 가져왔다는 것이다. 이렇게 엔티티 컨텍스트에서 관리되고 있는 엔티티를 수정해야 변경 감지가 동작하게 된다. 이를 짚고 넘어가는 이유는 아래와 같은 실수를 하는 경우가 있기 때문이다.
@Transactional
public void updateOrder(Long orderId, String name, OrderStatus orderStatus, Member orderMember){
Order order1 = orderRepository.findOne(orderId);
Order order2 = new Order();
order2.setId(order1.getId());
order2.setStatus(orderStatus);
order2.setMember(orderMember);
orderRepository.save(order2);
}
코드를 보면 새로운 엔티티 order2를 생성해주기는 하지만 order1의 id를 set 해주므로 결과적으로 동일한 업데이트 동작이 일어날 것 같다. 하지만 order2는 영속성 컨텍스트에서 관리되고 있던 엔티티가 아니다. 그러므로 엔티티의 변경 전 상태에 대해 알길이 없다. 이 상태에서 업데이트가 일어나면 order2에 set 해주지 않은 나머지 필드들은 다 null로 업데이트 되어버리는 불상사가 발생할 수 있는 것이다.
이를 방지하려면 수정시에는 무조건 첫번째 코드처럼 Repository로부터 리턴받은 엔티티를 통해 작업을 진행해야 한다. 그래야 엔티티 매니저가 관리하는 엔티티의 상태를 추적할 수 있고, 변경감지가 동작하게 된다.
persist와 merge
여기서 한 가지 설명하지 않고 넘어간 부분이 있는데, 위 두번째 코드에서 JpaRepository가 제공하는 save() 메서드는 내부적으로 어떻게 동작할까? 코드를 보자.
@Transactional
public <S extends T> S save(S entity) {
if (this.entityInformation.isNew(entity)) {
this.em.persist(entity);
return entity;
} else {
return this.em.merge(entity);
}
}
분기 처리가 되어있다. 엔티티가 새로운 엔티티면 persist()를, 아니면 merge()를 수행한다. 우선 엔티티 매니저는 1차 캐시와 DB를 차례대로 뒤진다. 만약 해당 엔티티 id를 가진 데이터가 없는 경우에는 persist()가 동작하게 되고, 있으면 merge()가 동작하여 해당 엔티티를 영속성 컨텍스트에 저장한다. 이제 트랜잭션이 커밋되면 엔티티 컨텍스트의 내용이 DB에 반영된다.
DB에도 같은 id를 가진 데이터가 없는 경우, save()를 수행하면 persist()가 동작한다. 하지만 동일한 id의 엔티티가 이미 존재하는 경우에는 merge()가 동작한다. 그러면 영속성 컨텍스트에 엔티티가 새로 영속화된 이후 DB에 커밋되는데 이때 덮어쓰기처럼 동작을 하게 되는 것이다. 따라서 신규 엔티티를 생성할 목적이 아니라면 save() 호출을 통한 수정은 지양하는 것이 좋다.
정리
- JPA에서 모든 CRUD 작업은 엔티티 매니저가 관리한다.
- 엔티티 매니저는 영속성 컨텍스트에서 엔티티의 상태를 관리한다.
- 새로 엔티티를 생성할때는 JpaRepository의 save()를 호출해도 되지만, 수정시에는 변경감지를 활용하자.
참고
김영한 저 자바 ORM 표준 JPA 프로그래밍
'IT > 개발지식' 카테고리의 다른 글
| Redis의 다양한 구성을 빠르게 따라해보자 (0) | 2021.06.14 |
|---|---|
| Git commit 이력을 깔끔하게 관리하는 2가지 방법 (0) | 2021.01.31 |
| DataJpaTest를 활용한 테스트 (0) | 2019.03.02 |
| Mockito를 활용한 단위테스트 (0) | 2018.11.14 |
| [자바스크립트] 최대값과 최소값 찾기 (0) | 2018.08.19 |