그동안은 상용 환경에서 in-memory cache를 주로 사용해왔다. 하지만 서버(인스턴스) 수가 많아질 경우에는 각 로컬 서버에 캐싱된 데이터가 전파되지 않으므로 히트율은 비약적으로 떨어지게 된다. 최근에 런칭한 서비스도 점차 트래픽이 많아지고 있어 scale-out을 논의하게 됐는데, 자연스럽게 remote cache 또한 구성하게 되었다.
Cluster와 Replication
사랑받는 오픈소스라면 HA(High Availibility)를 위한 여러가지 기술을 지원한다. Redis도 Cluster, Replica, Sentinel을 활용한 구성으로 HA를 보장한다. Cluster는 여러 노드에 데이터를 분산시키는 샤딩 기술이며 Replication은 데이터 유실을 최소화하기 위한 복사본 이중화를 뜻한다. Sentinel은 Redis cluster를 모니터링하며 failover를 지원한다.
Redis 5버전부터는 config 파일 몇 줄과 redis-cli를 통해 간단히 cluster와 replication을 구성이 가능하다.
Replication
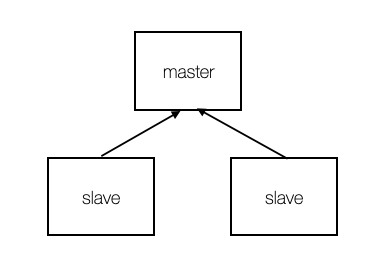
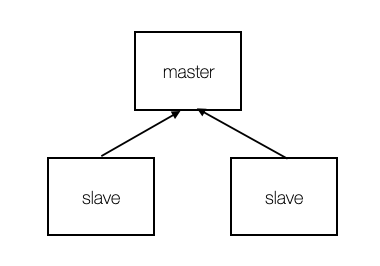
master 노드에 2개의 slave가 붙게 구성해보자. 이렇게 하면 master 노드의 데이터가 slave에 복사되어 데이터 유실의 위험성이 줄어들게 된다. redis.conf 파일을 같은 경로에 2개 복사한다. 그리고 master로 쓸 conf 파일을 아래와 같이 설정한다.
bind 127.0.0.1
port 6379
daemonize yes
여기서 bind는 요청을 받을 interface를 white list로 관리하는 개념이다. 위와 같이 입력하면 127.0.0.1(localhost)로부터 들어오는 요청만 redis에 접근할 수 있다. 다음으로는 slave의 conf 파일을 수정한다. 혹시 local이 아닌 원격 서버에 세팅을 하는 경우 이 옵션을 잘못주면 connection refuse가 발생할수 있다. protected mode도 함께 확인해보자(yes를 주면 명시된 interface에서만 접근 가능)
bind 127.0.0.1
port 6380(slave -1) / port 6381(slave-2)
replicaof 127.0.0.1 6379
daemonize yes
replicaof로 master의 port 번호를 명시해준다.
이제 차례대로 노드를 띄우면 된다.
app/redis>$ ./redis-server ../conf/redis-master.conf
app/redis>$ ./redis-server ../conf/redis-slave1.conf
app/redis>$ ./redis-server ../conf/redis-slave2.conf
redis node가 잘 떠있는지 확인해준다.
app/redis>$ ps -ef | grep redis
아래와 같이 master와 slave 노드들이 모두 구동중이다.

작동 테스트를 하려면 redis-cli를 쓰면 된다. master에 데이터를 넣으면 slave에 잘 복사되는지 확인해보자. 마스터 노드에 "test/test"라는 데이터를 넣어보자.
app/redis>$ ./redis-cli -p 6379

그 다음 slave 노드에서 데이터를 읽어본다.
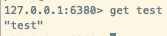
데이터가 slave 노드에 잘 복사되고 있다.
자바 클라이언트 설정
이제 자바로 클라이언트 세팅을 해보자.
많이 쓰이는 클라이언트는 두 가지가 있다. Jedis와 Lettuce이고 둘다 인기많은 오픈소스지만 최근에는 Lettuce를 쓰는 것으로 많이 기울어진듯하다. 유명한 창천향로님께서 직접 분석을 하신 글도 있으니 시간이 나면 읽어보자. 아무튼 Lettuce 기준으로 세팅을 해보겠다.
먼저 gradle 의존성 추가를 해준다.
implementation('org.springframework.boot:spring-boot-starter-data-redis')
implementation('io.lettuce:lettuce-core')
다음으로 application property를 설정해준다.
spring:
cache:
type: redis
redis:
host: 127.0.0.1
port: 6379
다음으로 자바에서 Connection Bean 설정을 해준다.
@RequiredArgsConstructor
@Configuration
public class RedisConfig {
private final RedisProperties redisProperties;
@Bean
public RedisConnectionFactory redisConnectionFactory() {
RedisStandaloneConfiguration standaloneConfiguration = new RedisStandaloneConfiguration();
standaloneConfiguration.setHostName(redisProperties.getHost());
standaloneConfiguration.setPort(redisProperties.getPort());
return new LettuceConnectionFactory(standaloneConfiguration);
}
@Bean
public RedisTemplate<?, ?> redisTemplate(RedisConnectionFactory redisConnectionFactory) {
RedisTemplate<String, Object> redisTemplate = new RedisTemplate<>();
redisTemplate.setConnectionFactory(redisConnectionFactory);
redisTemplate.setKeySerializer(new StringRedisSerializer());
redisTemplate.setValueSerializer(new StringRedisSerializer());
redisTemplate.setHashKeySerializer(new StringRedisSerializer());
redisTemplate.setHashValueSerializer(new StringRedisSerializer());
return redisTemplate;
}
}
아래 RedisTemplate 설정은 java <-> redis간 데이터를 읽고 쓸때 serialize, deserialize를 해주기 위한 설정이다. 이 정도로 하고 테스트 코드를 작성해서 정상적으로 연결이 됐는지 확인해본다. 테스트 코드는 아래와 같다.
@SpringBootTest
class RedisConfigTest {
@Autowired
RedisTemplate redisTemplate;
@Test
public void redisConnectionTest(){
final String key = "test";
final String data = "1";
final ValueOperations<String, String> valueOperations = redisTemplate.opsForValue();
valueOperations.set(key, data);
final String result = valueOperations.get(key);
assertEquals(data, result);
}
}
Lettuce 클라이언트를 통해 redis에 붙어서 데이터를 쓰고, 읽는 간단한 테스트다. 모든 세팅이 정상적으로 되었다면 테스트가 성공한다.

그런데, 자바 설정을 보면 알겠지만 사실 마스터에만 붙도록 설정을 할거라면 replica를 구성한 의미가 없다. 진정한 의미의 HA 구성을 위해 sentinel을 사용해야한다.
Sentinel
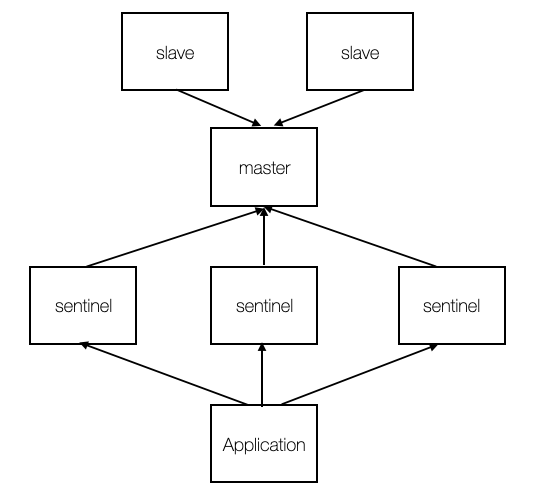
sentinel의 기본적인 기능은 failover다. master를 모니터링하다가 master가 죽었다고 판단될 시 slave를 master로 승격시킴으로써 redis의 availibility를 보장한다. sentinel 또한 여러가지 세팅 옵션이 있지만 공식문서를 참고해보기로 하고 기본적인 세팅으로 먼저 구성해보자. sentinel.conf 파일에서 아래 부분들을 찾아서 수정한다.
bind 127.0.0.1
protected-mode yes
port 26379
daemonize yes
pidfile "/app/redis/logs/redis_sentinel_26379.pid"
logfile "/app/redis/logs/redis_sentinel_26379.log"
sentinel monitor mymaster 127.0.0.1 6379 2
ip와 port는 redis master를 명시해주면 된다. quorum은 의사결정에 필요한 sentinel 수를 뜻한다. sentinel 3개를 띄울 것이므로 과반수인 2개가 동의한다면 의사결정이 진행된다.
slave config 파일을 복사했던것처럼 sentinel도 동일 설정으로 복사하돼, port 번호가 적혀있는 부분만 바꿔주면 된다. vi에서 아래 명령어로 문자열 일괄 대체가 가능하다.(26379를 모두 찾아 26380으로 변경)
:/%s/26379/26380
설정이 모두 끝났으면 차례로 구동시킨다.
app/redis>$ ./redis-sentinel ../conf/sentinel-26379.conf
app/redis>$ ./redis-sentinel ../conf/sentinel-26380.conf
app/redis>$ ./redis-sentinel ../conf/sentinel-26381.conf
sentinel이 정상 구동중인지 확인해본다.
app/redis>$ ps -ef | grep sentinel

잘 떠있다. redis-cli로 sentinel에 직접 접속해서 구동중인 sentinel의 설정 정보를 확인해보자.
127.0.0.1:26379> info sentinel
# Sentinel
sentinel_masters:1
sentinel_tilt:0
sentinel_running_scripts:0
sentinel_scripts_queue_length:0
sentinel_simulate_failure_flags:0
master0:name=mymaster,status=ok,address=127.0.0.1:6379,slaves=2,sentinels=3
잘 구성이 된것 같다. 이제 자바 설정만 해주면 된다.
먼저 sentinel의 property를 추가해준다.
spring:
redis:
host: 127.0.0.1
port: 6379
sentinel:
master: mymaster
nodes: 127.0.0.1:26379,127.0.0.1:26380,127.0.0.1:26381
lettuce:
shutdown-timeout: 200ms
다음 connection 설정 코드를 수정해준다.
이제 redis 연결을 맺을때 sentinel로부터 master 정보를 가져올 것이다.
@Bean
public RedisConnectionFactory redisSentinelConnectionFactory() {
RedisSentinelConfiguration sentinelConfig = new RedisSentinelConfiguration()
.master(redisProperties.getSentinel().getMaster());
redisProperties.getSentinel().getNodes().forEach(s -> sentinelConfig.sentinel(s.split(":")[0],
Integer.valueOf(s.split(":")[1])));
LettucePoolingClientConfiguration lettucePoolingClientConfiguration = LettucePoolingClientConfiguration.builder()
.build();
return new LettuceConnectionFactory(sentinelConfig, lettucePoolingClientConfiguration);
}
StandardAlone으로 설정때 작성했던 동일한 테스트를 돌려주면 아래와 같이 통과된다.
간혹 원격서버에 세팅을 할때 sentinel이 master 정보를 가져오지 못한다는(connection refused) 오류가 발생할때가 있다. 그런 경우sentinel 설정 파일에서 monitoring하는 master node 정보가 문제일 수 있으니 master의 host 정보를 다시 확인해보자. (동일 서버에서 master node와 sentinel이 구동중인 경우에도 127.0.0.1 을 인식하지 못하는 경우가 있다. 127.0.0.1이 아닌 해당 서버의 host ip로 수정해보면 문제가 해결될 수도 있다)
Clustering
데이터를 분산 저장하는 샤딩 기술이다. 대량의 트래픽을 처리할때 개별 노드에 병목이 발생되지 않도록 하여 성능상 이점을 얻을 수 있다. 아래와 같이 구성해보자.
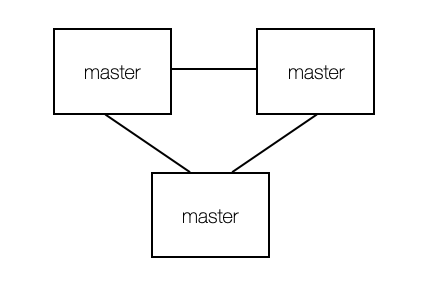
우선 conf 파일을 수정해준다.
cluster-enabled yes
cluster-config-file nodes.conf
cluster-node-timeout 5000
appendonly yes
클러스터링이 가능하도록 설정했다. appendonly 옵션은 데이터가 입력/수정/삭제될때마다 기록하겠다는 것이다. 노드 3개의 conf 파일을 모두 이렇게 세팅해준뒤 차례대로 구동해준다.
redis를 구동만시켜주면 알아서 클러스터링 되는 것이 아니므로 redis-cli를 통해 클러스터링 세팅을 해주어야 한다.
app/redis>$ ./redis-cli --cluster create 127.0.0.1:6379 127.0.0.1:6380 127.0.0.1:6381
추가적으로 replica를 두기 위해 --cluster-replicas 옵션을 주는 방법도 있다. 공식문서를 참고해보자.
자바에서는 아래와 같이 property와 config 파일만 수정해주면 된다.
spring:
redis:
host: 127.0.0.1
port: 6379
cluster:
nodes: 127.0.0.1:6370,127.0.0.1:6380,127.0.0.1:6381
@Bean
public RedisConnectionFactory redisSentinelConnectionFactory() {
RedisClusterConfiguration clusterConfiguration = new RedisClusterConfiguration(redisProperties.getCluster().getNodes());
LettucePoolingClientConfiguration lettucePoolingClientConfiguration = LettucePoolingClientConfiguration.builder()
.build();
return new LettuceConnectionFactory(clusterConfiguration, lettucePoolingClientConfiguration);
}
이렇게 세팅한 뒤 테스트를 돌려본다. redis-cli를 통해 직접 조회해보면 클러스터링된 노드중 하나로 데이터가 입력되는 것을 확인할 수 있다.
여러가지 redis 구성 방법을 알아보았는데, 실제 운영 서비스에서는 요구사항에 따라 이를 적절히 조합하여 안정적인 구성을 하면 된다. 다양한 테스트를 통해 최적의 구성을 찾아보자.
- 끝 -
참고
'IT > 개발지식' 카테고리의 다른 글
| Springboot yaml 파일에 List 세팅하기 (0) | 2021.08.05 |
|---|---|
| 객체지향 의존 역전 원리(DIP) 제대로 알기 (0) | 2021.08.02 |
| Git commit 이력을 깔끔하게 관리하는 2가지 방법 (0) | 2021.01.31 |
| JPA의 핵심 - 영속성 컨텍스트 훑어보기 (0) | 2020.09.26 |
| DataJpaTest를 활용한 테스트 (0) | 2019.03.02 |