
전체 글
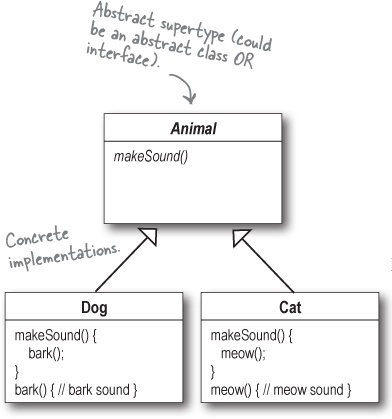
객체지향 의존 역전 원리(DIP) 제대로 알기
스프링+자바 코드를 보다 보면 흔하게 Service 인터페이스를 구현하고 있는 ServiceImpl 클래스 볼 수 있다. 물론 나도 컴퓨터공학 전공자로서 대학시절에 객체지향의 기본 원리에 대해서는 공부를 했지만 정작 실무를 접한 주니어 때는 왜 꼭 인터페이스-구현체 구조를 만들어야 되는지 제대로 이해하지 못했다. 물론, 인터페이스가 무엇인지는 알고 있었다. 그러니까 Dog도 Animal이고 Cat도 Animal이니까 결국 Animal로 묶어서 추상화할 수 있고 인터페이스로 공통된 규약을 정의할 수 있다는 개념이 아닌가. 하지만 인터페이스와 구현체가 1:1인 경우 딱히 다형성의 이점을 활용하는 것도 아니다. 이런 경우 꼭 인터페이스를 사용할 필요가 있겠냐는 생각이 들었고 실제 그렇게(인터페이스가 필요 없다..
Redis의 다양한 구성을 빠르게 따라해보자
그동안은 상용 환경에서 in-memory cache를 주로 사용해왔다. 하지만 서버(인스턴스) 수가 많아질 경우에는 각 로컬 서버에 캐싱된 데이터가 전파되지 않으므로 히트율은 비약적으로 떨어지게 된다. 최근에 런칭한 서비스도 점차 트래픽이 많아지고 있어 scale-out을 논의하게 됐는데, 자연스럽게 remote cache 또한 구성하게 되었다. Cluster와 Replication 사랑받는 오픈소스라면 HA(High Availibility)를 위한 여러가지 기술을 지원한다. Redis도 Cluster, Replica, Sentinel을 활용한 구성으로 HA를 보장한다. Cluster는 여러 노드에 데이터를 분산시키는 샤딩 기술이며 Replication은 데이터 유실을 최소화하기 위한 복사본 이중화를 뜻..
![스프링 배치 대용량데이터 처리 성능 개선기 [1편]](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdn%2FbZMrsg%2Fbtq0y1zrFrB%2FIYB7vMBvXuKln2ccWkR0s1%2Fimg.png)
스프링 배치 대용량데이터 처리 성능 개선기 [1편]
요구사항 혜택 고객 선정 모델을 통해 혜택 대상 고객들을 선정하고, 해당 고객들에게 쿠폰을 발급해주는 시스템을 구축해야 했다. 여기서 나는 일배치를 통해 집계된 대상 고객들에게 쿠폰을 발급하는 시스템을 설계하고 개발하기로 했다. 그런데 문제는 일별로 발급대상 데이터의 건수가 수십-수백만까지 예상되며 이를 3시간 내에 처리해야한다는 것이었다. 알던 이전에 구축해놓은 스프링 배치 서버가 있어 이를 활용해보기로 했고 전반적인 시스템 구조부터 그려봤다. Overall System Architecture 스프링 배치 관리/모니터링 도구로는 젠킨스를 활용하고 있다. 배치가 실행되면 대상고객이 집계되어있는 DB에서 타겟을 가져와서 쿠폰발급 서버에 1건 단위로 발급을 요청한다 발급 결과(쿠폰번호)를 받으면 데이터 집계..

Git commit 이력을 깔끔하게 관리하는 2가지 방법
Git을 처음 쓸때는 작업 이력을 저장하는 개념 정도로 commit을 이해하고 사용했었다. 그러다보니 commit 이력이 지저분해졌고, 다른 개발자들이 내 코드를 commit 단위로 리뷰하기 어려웠다. 또한 commit 단위로 수정 이력을 추적하는 것도 불가능해져 비로소 commit을 깔끔하게 관리하는데 공을 들이기 시작했다. 내가 주로 활용하는 방법은 2가지가 있다. 1. git stash 현재 작업중인 파일의 snapshot을 스테이징 영역에 잠시 보관해두는 명령이다. 개인적으로는 현재 브랜치의 작업이 완료되지 않은 상태에서 잠시 저장하고 다른 브랜치로 넘어가야 하는 상황에 주로 쓴다. 처음에는 이 명령어를 사용하면서도 혹시나 스테이징 영역이 날아가버리지는 않을지 불안하기도 했지만 다행히 아직까지 그..
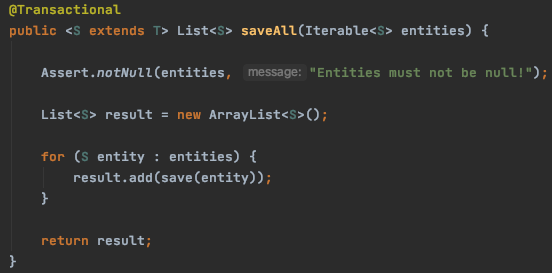
Spring Data JPA의 saveAll() 사용시 주의점
현재 개발 중인 배치 프로그램이 있는데 처리 과정이 모두 끝나고 마지막에 몇 만건의 데이터를 DB에 insert하는 과정이 있다. 대량의 데이터를 한꺼번에 처리해야되니 Spring Data에서 제공하는 saveAll()을 사용할 생각이었는데.. 얼마전 DBA께서 ERD를 보며 하신 말씀이 떠올랐다. "이 테이블은 commit 단위를 만 건 이하로 끊어주세요." saveAll을 호출하게 되면 몇 만건의 데이터가 한꺼번에 bulk insert 되기 때문에 데이터를 적절한 chunk로 나누어줄 필요가 있다는 것인데, 그 전에 saveAll의 내부 구현을 확인해보았다. saveAll 내부에서는 save를 반복 호출하는데, 두 메서드에 모두 @Transactional이 걸려있다. 이 경우 우선순위는 어디에 있을까..